RabbitMQ Concurrency
一、RabbitMQ可靠性投递与实践
1. RabbitMQ发送消息的几个环节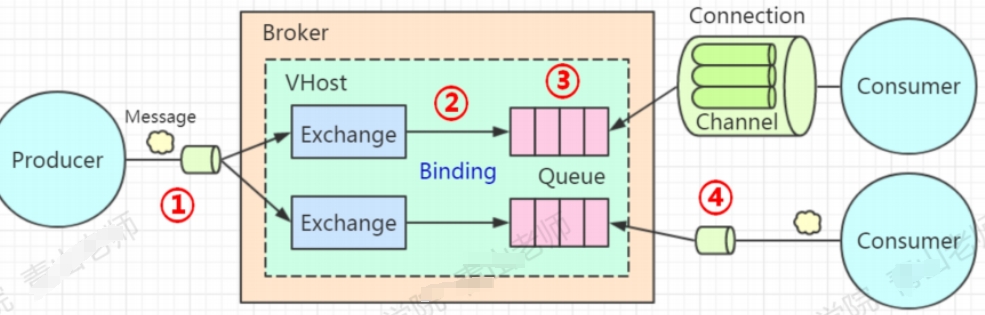
-
- 消息从生产者发送到Broker
- 消息从Exchange到Queue
- 消息在Queue中存储
- 消费者订阅Queue并消费消息
-
上面几个环节的可靠投递机制
-
- 生产者发送消息到Broker,可能会因为网络或者Broker问题(硬盘故障、满了)导致发送失败,生产者不确定Broker有没有正确收到。因此,RabbitMQ提供了两种机制服务端确认机制,服务端会通过某种方式返回一个应答,只要生产者收到这个应答就知道消息发送成功。
-
-
- Transaction(事务)模式
-
-
-
-
- 创建channel的时候,可以把信道设置成事务模式,如果channel.txCommit()的方法调用成功,就说明事务提交成功,则消息一定到达RabbitMQ中。
- 事务提交之前由于RabbitMQ异常或者其他原因抛出异常,可通过捕获使用channel.txRollback()实现事务回滚。
- Transaction模式中,只有收到服务端的Commit-OK的指令,才算提交成功
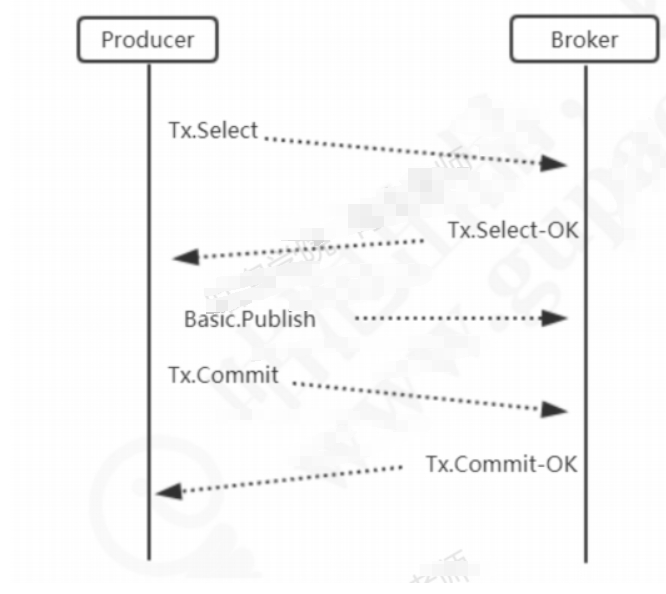
- 缺点:transaction模式是阻塞的,一条消息没有发送完毕,不能发送下一条消息,会窄干RabbitMQ服务器的性能。
-
-
-
-
- Confirm(确认)模式
-
-
-
-
- 确认模式有三种:
-
-
-
-
-
-
- 普通确认模式:生产者通过调用channel.confirmSelect()方法将信道设置为Confirm模式,一旦消息被投递到交换机之后(是否路由到队列没关系),RabbitMQ就会发送一个确认消息(Basic.Ack)给生产者,也就是调用channel.waitForConfirms()返回true,这样生产者就知道消息被服务端接收了。
- 批量确认模式:生产者开启Confirm模式后,先发送一批消息,只要channel.waitForConfirmsOrDie()方法没有抛出异常,就代表消息被服务端接收(只要有一个消息未被Broker确认就会IOException);批量确认模式两个问题:批量的数量不好确定,数量少的话,效率提升不上去;数量多的话,比如发送1000条消息才确认一次,如果前面999条消息都确认了,最后1条失败了,那么消息都要重发
- 异步确认模式:一边发送一边确认,添加一个ConfirmListener,并且用一个SortedSet来维护批次中没有被确认的消息。
-
-
-
-
- 消息从交换机路由到队列,可能失败的2种可能:routeKey错误或者队列不存在
-
-
- 处理方式有2种:
-
-
-
-
- 让服务端重发消息给生产者。生产这收到无法路由的消息可以做其他操作
- 让交换机路由到另外一个备用交换机。在创建交换机的时候可以指定备份交换机。(注意队列可以指定死信交换机;交换机可以指定备份交换机)
-
-
-
- 消息在队列存储,第三个环节是消息在队列存储,如果没有消费者的话,队列一直存储在数据库中。如果RabbitMQ的服务或者硬件发生故障,可能会导致消息丢失,因此我们要把消息和元数据(队列,交换机,绑定)都保存磁盘
-
-
- 交换机持久化
- 队列持久化
- 消息持久化
- RabbitMQ服务集群
-
-
- 消息投递到消费者,如果消费收到消息后没来得及处理或者处理过程发生异常,会导致失败。RabbitMQ服务端需要知道消费者对消息的接收情况,并决定是否重新投递。RabbitMQ提供消费者的消息确认机制,自动或者手动发送ACK给服务端
-
-
- 自动ACK,这个事默认情况,消费者会在收到消息的时候就自动发送ACK。注意不是方法执行完毕时才发送ACK。
- 手动ACK,如果需要等待消息消费完毕或者执行完毕才发送ACK,需要把自动ACK设置成手动ACK。其他,特殊情况如果消费者无法处理消息,可以拒绝消息:Basic.Reject()单条拒绝,Basic.Nack()批量拒绝
-
2. MQ的一些使用特性
-
- 生产者如何知道消费者消费成功?一般有两种方式:
-
-
- 消费者收到消息处理完毕后,调用生产者的API(破坏了解耦)
- 消费者收到消息处理完毕后,发送一条响应消息给生产者
-
-
- 补偿机制
-
-
- 生产者的API没有被调用或者没有收到响应消息?需要由服务端定时重新发送,设计定时重发需要设计几个参数:
-
-
-
-
- 间隔多久重发,一般可设置衰减机制
- 重发多少次
-
-
-
- 消息幂等性
-
-
- 为了避免消息的重复处理,一般在消费端控制。
- 出现消息重复可能原因:
-
-
-
-
- 生产者重复投递
- 消费者未发送ACk或者其他原因,导致消息重新消费
- 生产者代码或者网络问题
-
-
-
-
- 解决办法
-
-
-
-
- 对于重复发送的消息,对每条消息生成一个唯一的业务ID,通过日志或者消息落库来做重复控制。
-
-
-
- 最终一致性
-
-
- 如果消费者宕机或者出现BUG,尝试多次重发后,消息没有得到处理。
- 定时处理或者人工补偿
-
-
- 消息顺序性
-
-
- 是指消费者消费消息的顺序跟生产者生产消息的顺序一致的。例如:1、发表微博 2、发表评论 3、删除微博。顺序不能颠倒
- 一个队列有多个消费者时,由于消费速度是不一致的,因此顺序无法保证。一个队列仅有一个消费者的情况下才能保证顺序消费
-
3. 集群与高可用
-
- 为什么要做集群?
-
-
- 高可用,如果集群中某些MQ服务器不可用,客户端还能连接到其他MQ服务器,不影响业务
- 负载均衡,在并发的场景下,单台的MQ处理消息有限,可以分发给多台MQ服务器,减少消息延迟
-
-
- RabbitMQ如何做集群?
-
-
- RabbitMQ的节点类型
-
-
-
-
- 磁盘节点:将元数据放在磁盘中。未指定类型的情况下,默认磁盘节点。
- 内存节点:将元数据放在内存中,如果是持久化的消息,会同时存放内存和磁盘
-
-
-
-
- 概念解释:
-
-
-
-
- 元数据:包括队列名字属性,交换机类型、名字属性、绑定、vhost定义
- 集群中至少需要一个磁盘节点来持久化元数据,否则全部内存节点崩溃时就无法同步元数据。我们一般把应用连接到内存节点,磁盘节点用来备份
-
-
-
-
- RabbitMQ的集群模式
-
-
-
-
- 普通集群模式
-
-
-
-
-
-
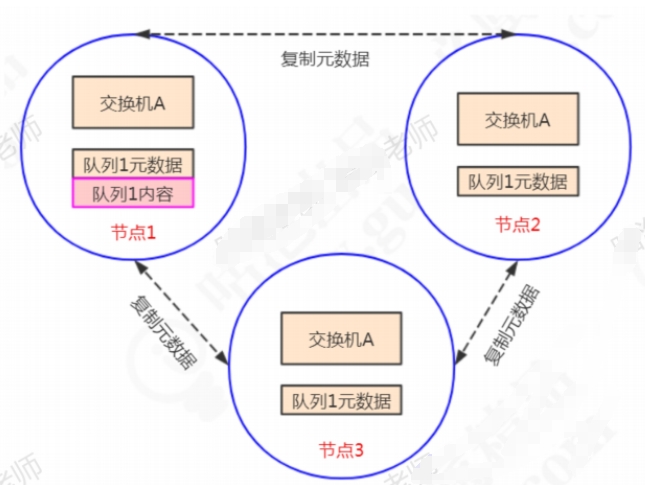
- 普通集群模式下,不同MQ节点之间只会同步元数据(队列名字属性,交换机类型、名字属性、绑定、vhost定义)而不会同步消息
- 缺点:只要节点1挂了,队列1的所有数据都丢失了,为什么不直接把消息在所有节点都复制一份呢?主要出于浪费存储空间和同步数据的网络开销问题。如果需要保证队列的高可用,就不能用这种集群模式
-
-
-
-
-
-
- 镜像集群
-
-
-
-
-
-
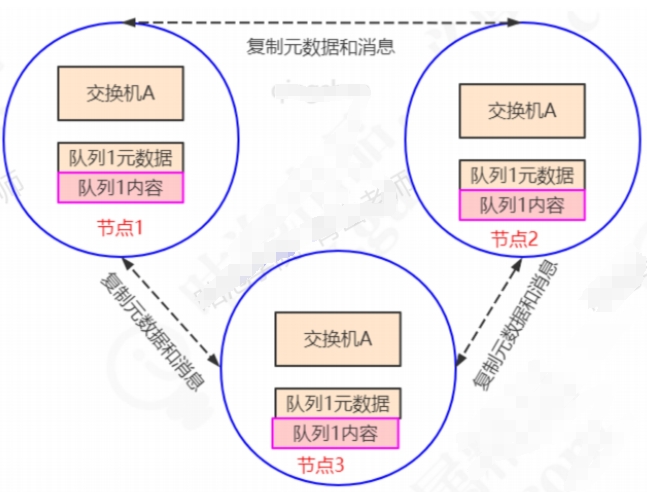
- 镜像队列模式下,消息内容会在镜像节点间同步,可用性更高。不过也有一定的副作用:系统性能会降低,节点过多的情况下同步代价比较大
-
-
-
-
- 高可用
-
-
- 集群搭建成功后,如果存在多个内存节点,生产者和消费者应该连接到哪个内存节点呢?我们需要一个负载均衡组件(HAProxy、LVS、nginx)来做路由。这时生产者和消费者只要路由到负载组件的IP即可。
- 负载均衡分为四层负载和七层负载
-
-
-
-
- 四层负载:工作在OSI模型的第四层,即传输层,根据IP和端口进行转发(LVS支持四层负载)
- 七层负载:OSI模型的第七层,应用层。可以根据请求资源类型分配到后端服务器(nginx支持七层负载,HAProxy支持四层和七层负载)
- 负载软件本身也需要集群,也会面临同样选择哪个负载组件的问题?

-
-