Kafka Basic
Kafka
一、Kafka使用场景
- 消息传递,实现异步、解耦、削峰
- 大数据领域,比如网站行为分析。Kafka不仅仅是一个简单的消息中间件,而是一个流处理平台。在Kafka里面消息被称为日志。一般把Kafka的数据导入Hadoop、HBase等离线数据仓库,实现数据分析
二、Kafka和ZK的关系
- Kafka在安装时依赖ZK服务,主要利用ZK的有序节点,临时节点和监听机制。帮助Kafka做以下事情:配置中心(管理broker、topic、partition、consumer的信息,包括元数据的变动)、负载均衡、命名服务、集群管理和选举
三、Kafka架构分析
- Broker:Kafka作为一个中间件,主要功能存储和转发数据。默认端口9092,生产者和消费者都需要和这个Broker建立一个连接
-
消息
-
- 客户端之间传输的数据叫做消息,或者叫做记录
- 消息在传输的过程中需要序列化
- 消息在服务端的存储格式(RecordBatch和Record)
-
生产者
-
- 发送消息的一方,为了提高消息的发送速率,生产者不是逐条发送消息给Broker的,而是批量发送的。由参数:batch.size决定
-
消费者
-
- Kafka只支持pull模式。
- 为什么Kafka消费用pull模式?原因是在push模式下,如果生产者产生消息的速度远远大于消费者消费的速率,那消费者会不堪重负。
- 消费者可以控制一次到底获取多少条消息,由参数:max.poll.records决定,默认500
-
Topic
-
- 生产者和消费者通过队列关联起来,在Kafka里面队列叫做Topic,是一个逻辑概念,可以理解为消息的集合
- 生产者发送消息时,如果Topic不存在,会自动创建,由参数auto.create.topics.enable控制,默认为true
-
Partition和Cluster
-
- 一个Topic中的消息如果太多,会带来两个问题:
-
-
- 第一个不方便扩展横向扩展,比如我们想要在集群中把数据分布在不同的机器上实现扩展,这个是做不到的
- 第二个是并发和负载的问题,所有客户操作的都是同一个Topic,在高并发的场景下性能会大大下降
-
-
- 增解决这个问题呢?
-
-
- Kafka引入一个分区(Partition)的概念,一个Topic可以划分成多个分区。
- 在创建Topic时指定,每个Topic至少有一个分区。
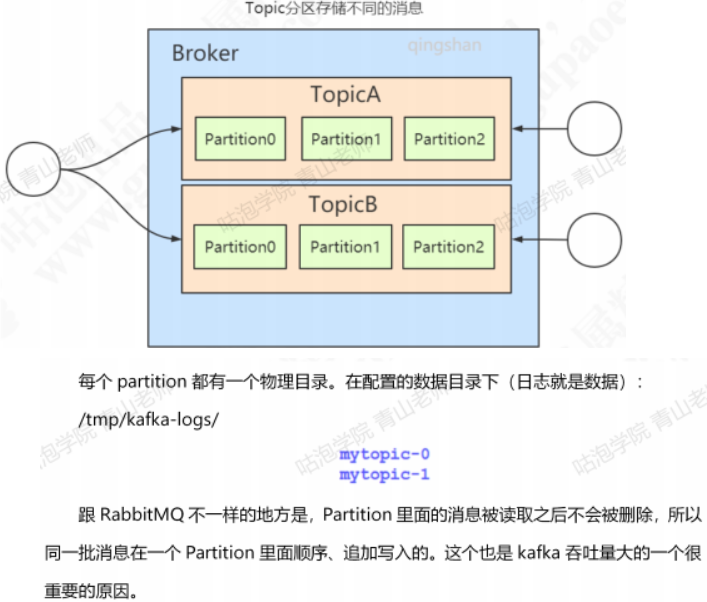
- Partition副本Replica机制
-
-
-
-
- 如果Partition的数据只存储一份,在发生网络或硬件故障时会导致分区无法访问或者恢复
- Partition可以有若干个副本(Replica),副本必须在不同的Broker上面。一般我们说的副本包括其中的主节点。由参数:replication-factor指定一个Topic的副本数。
- 举例:
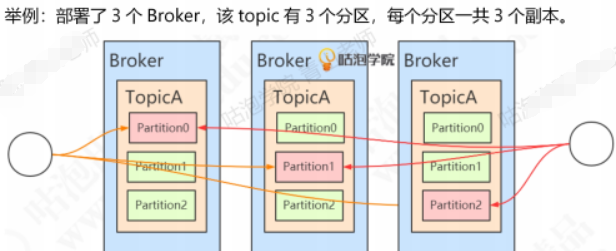 存放相同数据的Partition有leader和follower的概念。leader在哪一台机是不一定的,选举出来的。
存放相同数据的Partition有leader和follower的概念。leader在哪一台机是不一定的,选举出来的。 - 生产者发消息和消费者读消息都是针对leader
-
-
-
-
- Segment(段)
-
-
-
-
- Kafka的数据时存放在后缀.log的文件里面的,如果一个Partition只有一个log文件,也会变的越来越大,这时检索效率也会很低。
- 所以Partition再 做一个分片,单位叫Segment(段)。Kafka的存储文件就是按照段来划分的存储的
-
-
-
-
- Consumer Group
-
-
-
-
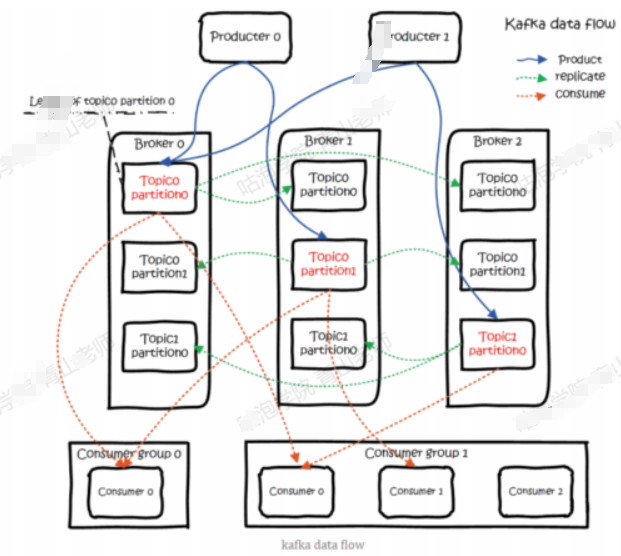
- 如果有多个消费者,怎么知道消费的是同一个Topic呢?我们引入了一个Consumer Group消费组的概念,通过group id来配置。注意:消费同一个Topic的消费者不一定是同一个组,只有group id相同的消费者才是同一个消费组
- 注意:同一个group中消费者,不能消费相同的Partition。Partition要在消费者之间分配。如果消费者比Partition少,一个消费者可以消费多个Partition。如果消费者比Partition多,肯定有消费者没有Partition可以消费,不会出现一个group里面的消费者消费相同一个Partition的情况
-
-
-
-
- Consumer Offset
-
-
-
-
- Partition里面的消息是顺序写入的,读取之后不会被删除。为了避免出现重复消费的情况,我们对消息进行编号,用来标识一条消息的唯一
- 这个编号我们叫做offset,偏移量。offset记录着下一条将发送给Consumer的消息的序号。这个偏移量直接保存在服务端
-
-
-
-
- 架构例子
-
-
-
四、Kafka集成Canal实现数据同步
- 工作流程:数据变动–产生binlog信息–canal服务端获取binlog信息–发送MQ消息–消费者消费MQ消息–完成后续逻辑处理
五、进阶功能
-
消息幂等性
-
- 解决消息的幂等性依赖于生产者的消息的唯一标识,kafka在Broker实现了消息的重复性判断。那么这个标识是怎么产生的呢?enable.idempotence设置成true,Producer自动升级成幂等性Producer。Kafka会自动去重
- 实现机制:
-
-
- PID(Producer ID)幂等性的生产者每个客户端都有一个唯一的编号
- Sequence Number,幂等性的生产者发送每一条消息都会携带相应的Sequence Number,服务端就是根据这个值来判断是否重复,如果值比服务端记录的小,消息肯定是重复了
- Sequence Number并不是全局有序,作用范围有限:
-
-
-
-
- 只能保证单分区上的幂等性,即一个幂等性Producer能够保证某个Topic的一个分区不出现重复的消息
- 只能实现单会话上的幂等性,指的是Producer进程的一次运行,当Producer进程重启后,幂等性不保证
-
-